1. Order Complexity Analysis #
Created Sunday 05 January 2020
The idea is to quantify the quality of the solution, in terms of time(steps) and space(memory).
- Time - This is very very important.
- this is very important from a commercial perspective.
- This is the primary reason why we are studying different algorithms for the same problem.
- The user can buy hardware but he can’t afford a slow system.
Scenario:
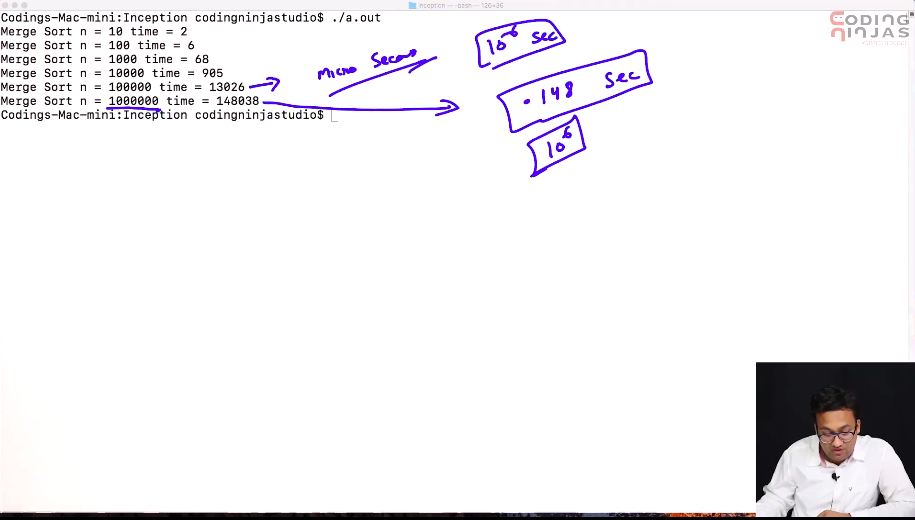
- Experimental Analysis: For a given algo the **simplest **method is to note the running time for input size 1, 10, 100, 1000 etc. Plot the graph and we can figure out the expression for time for a given n. F(n) = an + b (say). Or some other function.
**Confidence Boost: **Ankush has done the same thing which I did in semester IV. He used time(0). Yeah!!!
For 0.1 million, Merge sort ~ 0.15 seconds
Selection sort ~ ( Hrs) 2400 seconds (Investment in algos is worth it)
- Issues with experimental analysis:
- Time is not exactly the same for the same input. This is because of the distribution of RAM, processes running. Too much dependency on the machien, resources.
- We need to be sure of the test case’s nature, i.e the input should not be favourable to any of the algorithm. This is very difficult.
- We need to code each solution, this is very painful. Stupid way to do this. Not intelligent at all.
- Very very Time consuming, we would have to wait for all algos to finish, and if they do. Also small inputs don’t have much difference, hence they cannot be used anyway.
Hence, we won’t be doing this.
- Theoretical analysis**(This is a gold mine)**:
In this, we don’t need to take into account, the computer, or resources etc. Our pseudocode/algorithm is enough to find the time complexity.
This makes sense, as we think of the solution, then why to use experimentation to calculate time. This is one important thing we can do, for algorithms, at least.
- We need to learn Asymptotic notation for this.
Important Note: Suppose some algorithm takes 5 n^2^, is this accurate in seconds. No, but it is the steps(i.e no. of unit operations) that we will be doing. So, machine dependency can be ignored altogether. Confidence Boost: I thought the exact same, this is the best feeling.
For a function f(n). Big Oh is a way to give an upper bound.(May or may not be worst case). g(n) is O(f(n)), if g(n) <= k * f(n) for large values and a positive k. In Big Oh notation, we write:
- Number of unit operations.
- Only highest power term matters.
- We don’t care about the coefficients.
Q) Find largest element in an array. A) Can be done in single scan. We do (k constant) operations for each number. So k*n.This is theta(n). Hence it is also O(n).
Things like initialization, etc is constant, so it is ignored.
Q) Bubble sort for input size n. A) Suppose we swap every time. sigma(n-i) i=1 to n -> O(n^2^).
- Remember, if multiple variables are present, we cannot equalize them. Because different things have different bounds.
- If multiple things are involved, keep the parameters differnt. Equalizing paints a false picture.
- In Big Oh notation, only constants and **dormant **terms are discarded, nothing else.